遇到的问题
我想在数据库中存一个被转化为Base64字符串的SHA256哈希值,我在想要用什么类型的值来存储,是用Text还是char[n],这实际上和base64编码的长度有关,于是就查了下wiki。
编码原理
编码其实是基于一个64个数值的编码表(图源维基百科):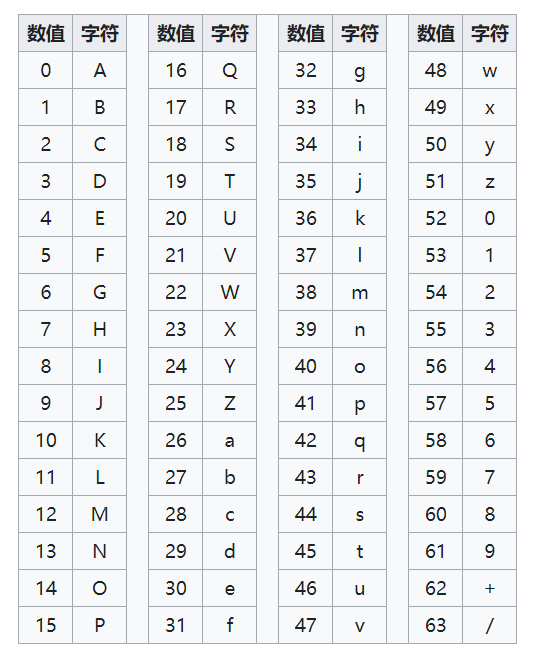
也就是说每一个base64字符能够表示6bit的内容(2的6次方为64),换句话说,每4个base64字符(4 * 6 = 24)可以表示3(3 * 8 = 24)字节的内容。
如果原始的字节数不是3的倍数,比如4字节(剩余1字节)或者5字节(剩余2字节),则需要再末尾处理,一共可以分为2种情况。
如果剩余1字节,需要补2字节(16bit)才是3的倍数。也就是要则补16个0,加上前面剩余的1字节(8bit),一共是24个bit,其中24个bit的前12bit(2*6)构成两个base64字符,剩下的12bit(2*6)全部是0,用两个等号 == 表示。
如果剩余2字节,需要补1字节(8bit)才是3的倍数。也就是要则补8个0,加上前面剩余的2字节(16bit),一共是24个bit,其中24个bit的前18bit(3*6)构成三个base64字符,剩下的6bit(1*6)全部是0,用一个等号 = 表示。
如图所示(图源维基百科):
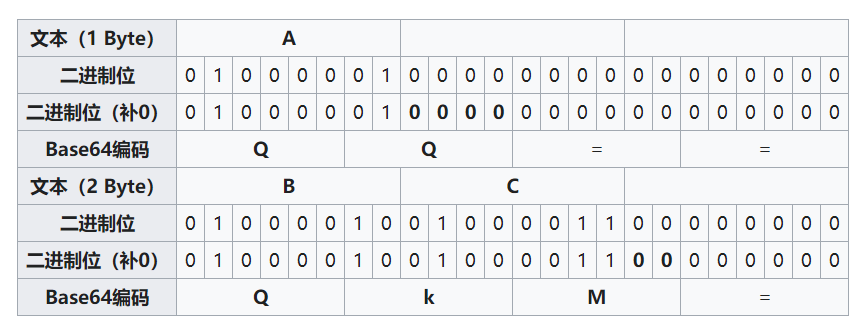
也就是说,原始数据不够3字节就会补全到3个字节,这3个字节会相应地转化为4个base64字符。
结论
所以说最后的计算公式应该是:
向上取整(原始字节数 / 3) * 4
而SHA256的结果一共是256bit,也就是32字节,根据上述公式,最后的base64编码长度应该是44字节,应该使用char[44]存储。
验证
写个脚本验证一下:
1 | from hashlib import sha256 |
输出结果:
1 | 公式计算长度: 8 |
与理论值相符合。
参考资料:Base64 - 维基百科,自由的百科全书 (wikipedia.org)
本文地址: https://www.chimaoshu.top/base64编码字符串的长度计算方法/
版权声明:本博客所有文章除特别声明外,均采用 Apache License 2.0 许可协议,转载请注明出处。