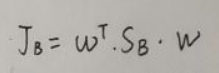浅析比特币中的数据结构
block chain
从整体上看,block chain是由哈希指针连成的链表。如图所示,除了创世纪块以外,每一个区块都有指向上一个区块的哈希指针,同时最新产生的区块也会有一个哈希指针指向他,只是还未被记录到下一个区块中。
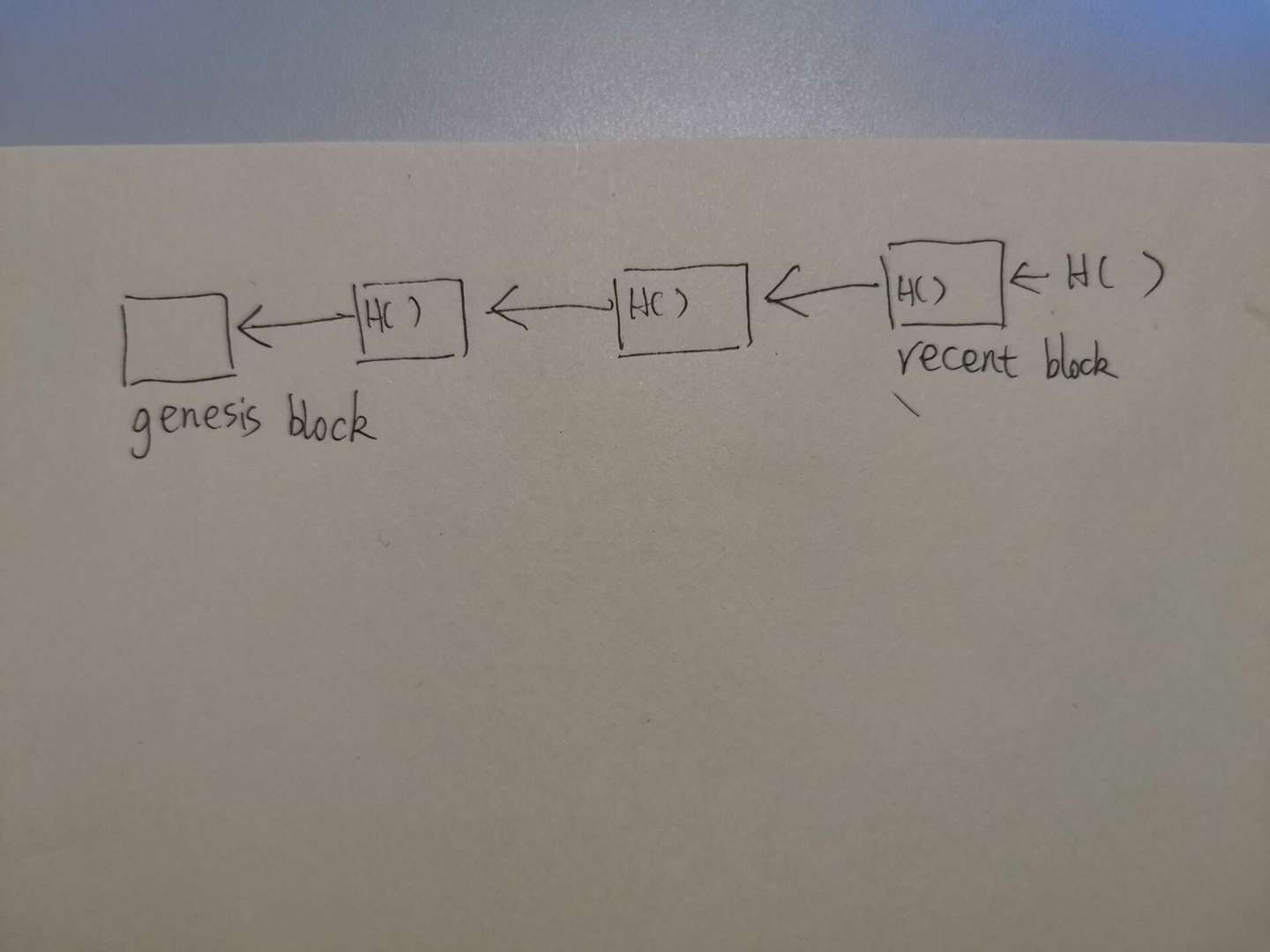
值得一提的是,指向一个区块的哈希值由在此之前的所有区块共同作用。之所以说是“在此之前的所有区块共同作用”,是因为每个区块的block header都会存储上一个区块的哈希值,而计算区块的哈希值又需要整个block header的参与,上一个区块的哈希值自然包含在里面。
因此,只要某一个区块发生了篡改,后续的所有区块的哈希值都需要进行相应的修改,才能使得哈希指针能够对上。这个数据结构的好处是,只要存储最后一个哈希指针,就能检测前面所有的区块是否被篡改过,这是区块链不可篡改性的基石。
block body
顾名思义,block body是每一个区块的身体部分,它存储了由矿工打包的一些交易。整体上看,block body是由一课Merkle Tree构成的。
Merkle Tree,构成block body的数据结构。类似二叉树,但是这里的指针是哈希指针而非普通的指针。block body需要存储每一笔交易的具体内容,这些交易的具体内容都存储在Merkle Tree的叶子节点中。而每一个叶子节点都会生成哈希,兄弟节点之间的哈希会再进行一次哈希,生成父节点的值,以此类推,最终生成一个根哈希值(root hash),存储在block header中。
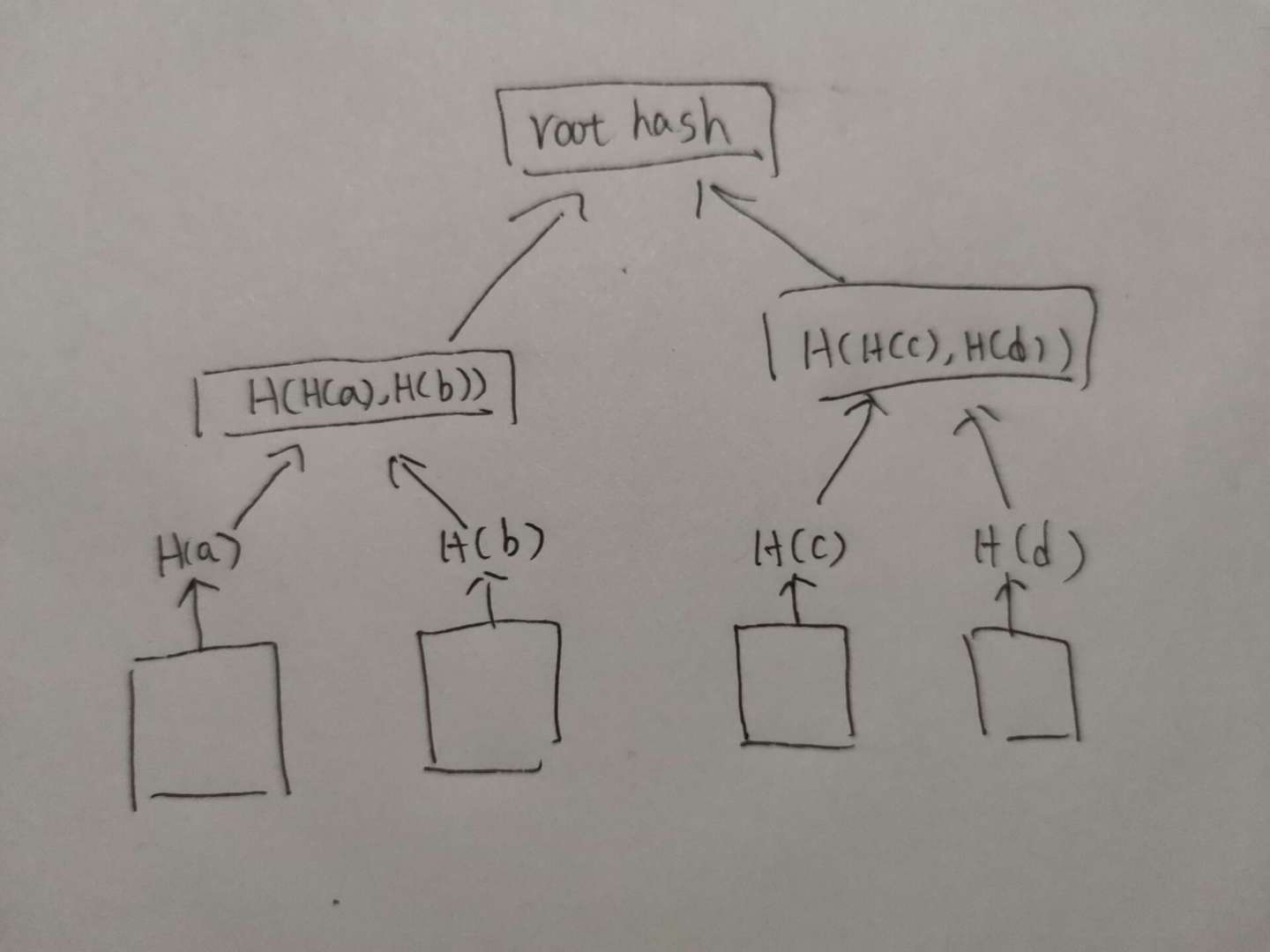
这种数据结构有什么好处呢?首先,我们只要存储一个root hash就能判断每一笔交易(即叶子节点)是否被篡改,这并不难理解。
其次,我们可以进行所谓的Merkle Proof,即证明某一笔交易是否被写到区块链中。在比特币这个去中心化的世界中,每个设备都是一个节点。挖矿的矿工属于全节点,他们的设备上存储了从创世纪块到现在的所有区块的block header与block body。而比特币钱包属于轻节点,与全节点不同的是,轻节点只存储block header,而不存储block body。前面说到,root hash会存储在block header里面,因此轻节点拥有root hash的内容。当你使用比特币钱包做了一次转账,轻节点(比特币钱包)需要检查转账是否被写在区块链里面,那么钱包会向全节点发起一次请求,由全节点返回对应路径上的哈希(如上图所示,如果想要检查a交易是否被写到区块里面,那么全节点会返回H(b)与H(H(c), H(d))),这样轻节点就可以在O(logN)的时间复杂度内算出root hash,检查其与本地存储的block header里面存储的信息是否一致,如果一致,则证明交易已经被存储到区块中。
block header里面并没有亮眼的数据结构,但它存储的信息仍然十分重要,我们不妨看看:
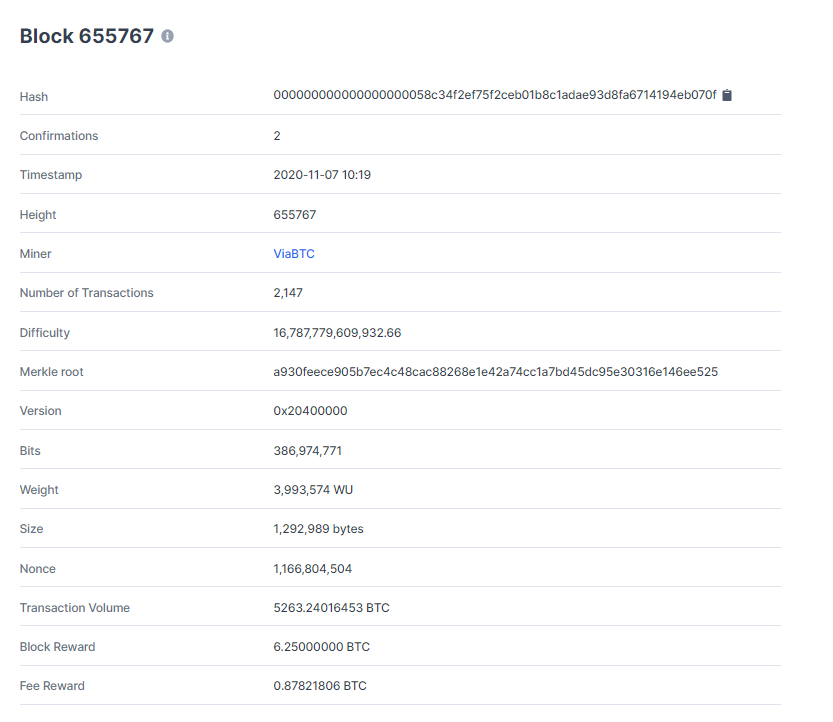
这是来自https://www.blockchain.com/btc/block的区块链信息,是7分钟前刚被矿工挖到的一个区块。可以看到里面存储了很多信息,比如我们前面提到的,整个区块链的哈希,以及Merkle root的哈希,还有出块的时间、挖矿得到的比特币奖励、矿工小费、协议版本等信息。
本文地址: https://www.chimaoshu.top/浅析比特币中的数据结构/
版权声明:本博客所有文章除特别声明外,均采用 Apache License 2.0 许可协议,转载请注明出处。